Hi, I'm Kevin. I solve complex problems using technology and data.
In my day job I work as a partner solutions leader at Databricks where I help our consulting partners build Data and AI solutions on the Data Intelligence Platform.
In my evenings I'm a lecturer at UC Berkeley where I teach and advise students working on their Data Science Capstone projects.
My speciality is formulating high-impact solutions that leverage technology innovation. I've inspired, influenced, and led the creation of hundreds of digital products; working from both inside and alongside teams of researchers, scientists, designers, engineers and enthusiasts.
I'm lucky to have worked with and been taught by some really brilliant people. Some of them have a few words to share.
I get my hands dirty a lot in the technical details. But I also have the acumen to manage the 10,000 foot view in a room with executives. My leadership experience includes:
When I'm not spending time working on my next project, I'm an avid cook and aspiring family photographer. My favorite subjects (and taste-testers) are my wife and two children. With my family I also love to travel.
Wherever I go, I carry with me a master’s degree in Information and Data Science from UC Berkeley. I also have in my backpack a bachelor’s degree in Electrical and Computer Engineering from the University of Illinois at Champaign-Urbana.
Data Science Capstone

In the last few weeks of the 2020 election it was becoming increasingly difficult to reach a particularly elusive group of people - the undecided voter. Read more
The grassroots organization People's Action wanted to find undecided voters so they might have an important discussion. The purpose: to change hearts and minds using an empathy-driven persuasion method called Deep Canvassing.
Communication Unbreakdown, our Data Science capstone team, has paired grassroots organizing with cutting-edge data science to help community organizers reach target populations for civic engagement. Our solution helped People’s Action reach 33% more conflicted voters in the last two weeks of the U.S. presidential election in five key swing states where the technology was used.
The technology was also used for the Georgia Senate runoff. During the final days of voting, conflicted voters were found in 45% of people contacted compared to a human-informed control group of 18%.
 Civis Platform
Civis Platform
 Thrutalk
Thrutalk
 Zapier
Zapier
 Amazon SageMaker
Amazon SageMaker
 Amazon
Amazon  Apache Spark
Apache Spark
 D3.js
D3.js
 Flask
Flask
 Python
Python
 Data Pipelines
Data Pipelines
 Exploratory Data Analysis
Exploratory Data Analysis
 Feature Engineering
Feature Engineering
 Supervised Machine Learning
Supervised Machine Learning
 Reinforcement Learning
Reinforcement Learning
Deep Learning | NLP

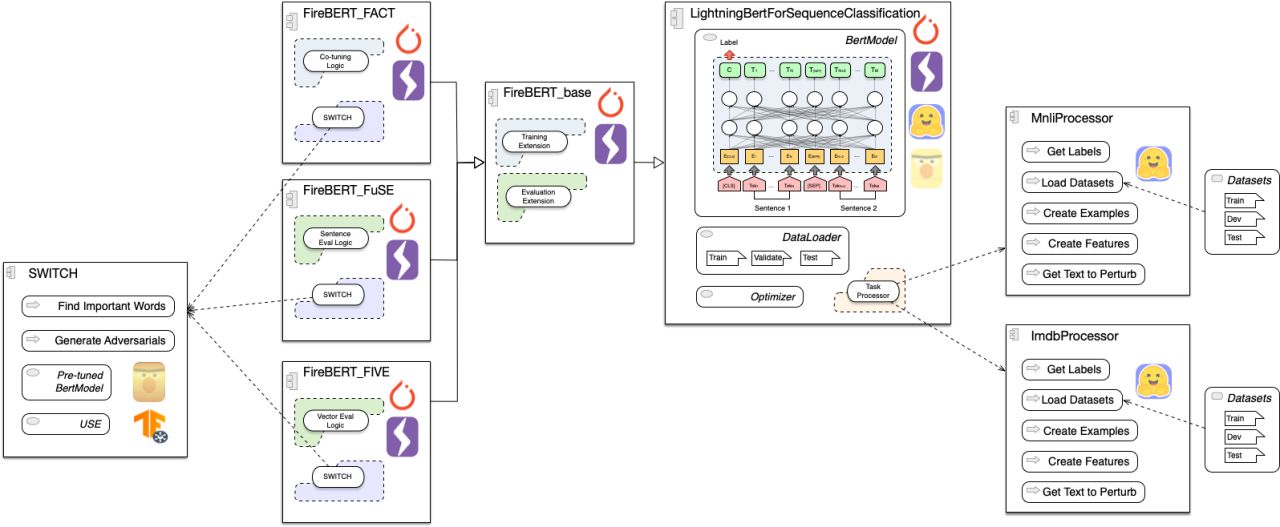
The introduction of BERT in 2018 has brought natural language understanding to a level where it quickly became the standard for real-world classification tasks. But with broad adoption comes an attractive attack surface. Read more
The 2019 project “TextFooler” used word-similarities to generate samples that near-completely fool BERT-based classifiers. Thus, our research starts with the question: “Is it possible to build a firewall to protect BERT?"
Our resulting body of work, FireBERT, consists of three classification techniques to harden BERT against adversarial attack. Published in the Springer Series Advances in Information and Communication for FICC 2021, FireBERT is evaluated against MNLI and IMDB Movie Review tasks, and demonstrates it is possible to harden BERT against 95% of adversarial samples without significantly reducing the performance of regular benchmarks.
 PyTorch
PyTorch
 PyTorch Lightning
Python
PyTorch Lightning
Python
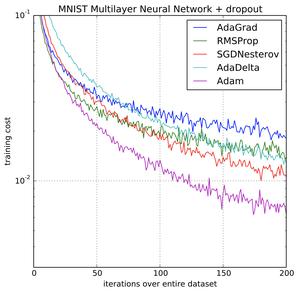 Adam
Adam
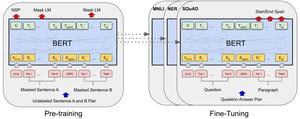 BERT
BERT
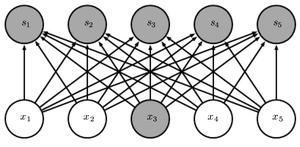 Dense Connections
Dense Connections
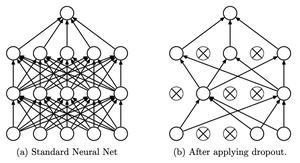 Dropout
Dropout
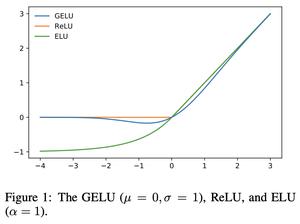 GELU
GELU
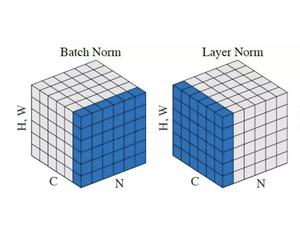 Layer Normalization
Layer Normalization
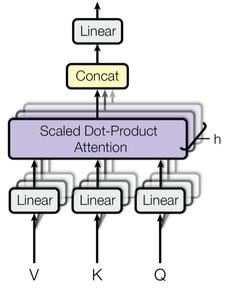 Multi-Head Attention
Multi-Head Attention
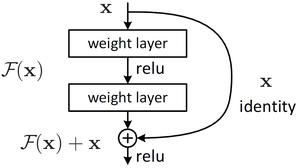 Residual Connection
Residual Connection
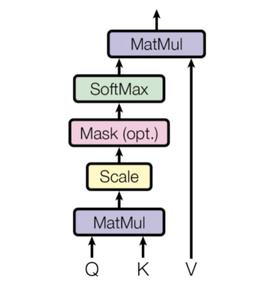 Scaled Dot-Product Attention
Scaled Dot-Product Attention
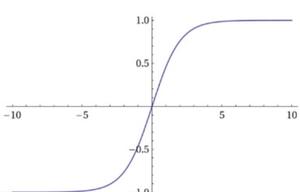 Softmax
Softmax
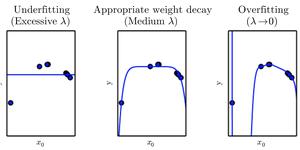 Weight Decay
Weight Decay
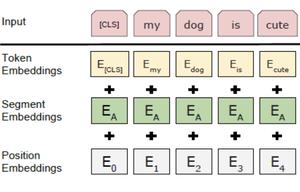 WordPiece
WordPiece
Machine Learning at Scale | Spark
Flight delays create problems in scheduling for airlines and airports, leading to passenger inconvenience and huge economic loss. As a result there is growing interest in predicting flight delays beforehand in order to optimize operations and to improve customer satisfaction. Read more
In this project, two massive datasets were obtained consisting of five years of national flight and weather data. The focus of my work for the project was in developing a data pipeline consisting of a multi-zone data lake, a multi-stage cleanup and data transformation process, complex queries and window joins, and the engineering of novel features used in model building and prediction. The pipeline was built in Databricks using Delta Lake, Spark SQL and PySpark.
 Databricks
Databricks
 Delta Lake
Delta Lake
 PySpark
PySpark
 Spark SQL
Python
Data Pipelines
Exploratory Data Analysis
Feature Engineering
Supervised Machine Learning
Spark SQL
Python
Data Pipelines
Exploratory Data Analysis
Feature Engineering
Supervised Machine Learning
Data Visualization | Tableau
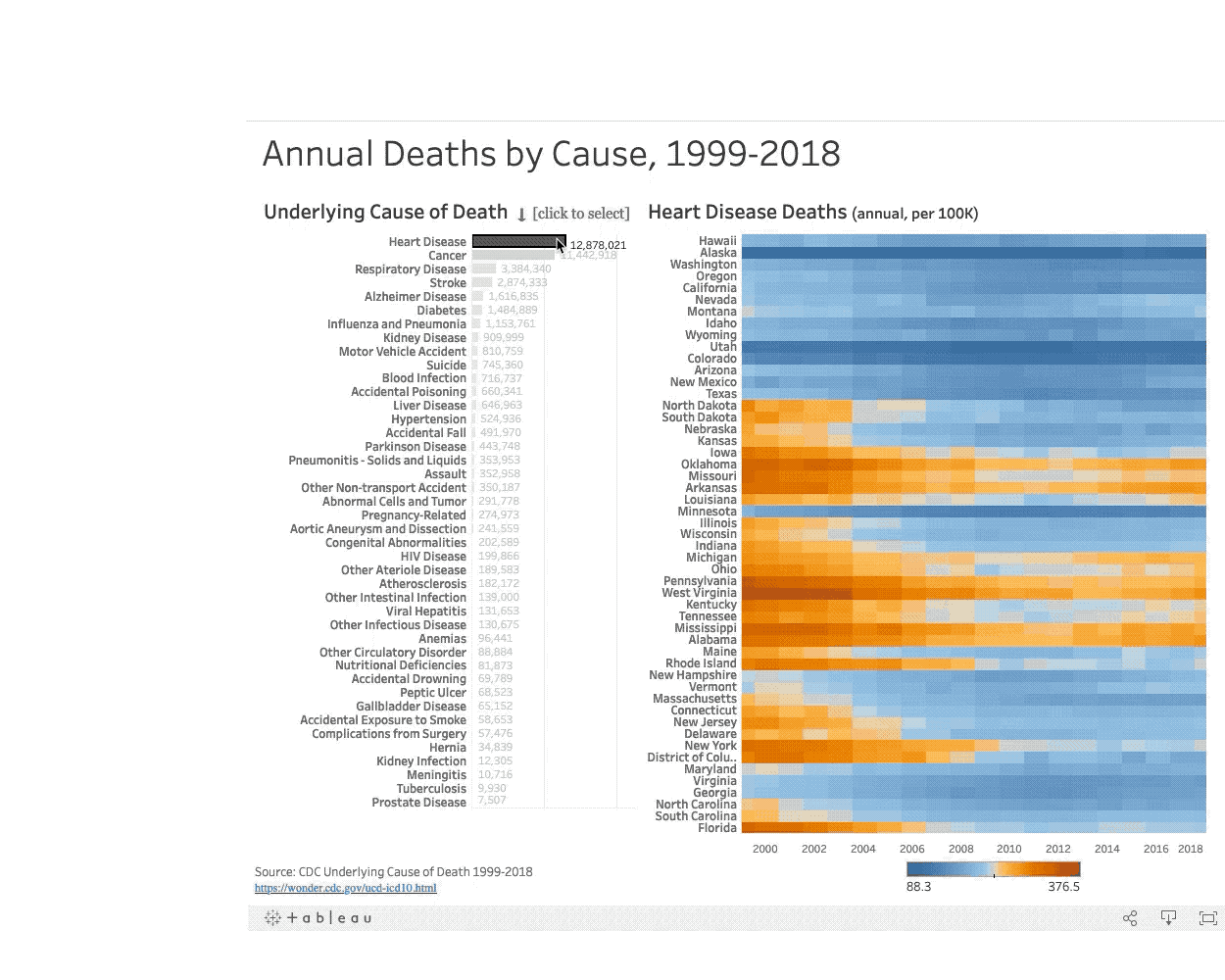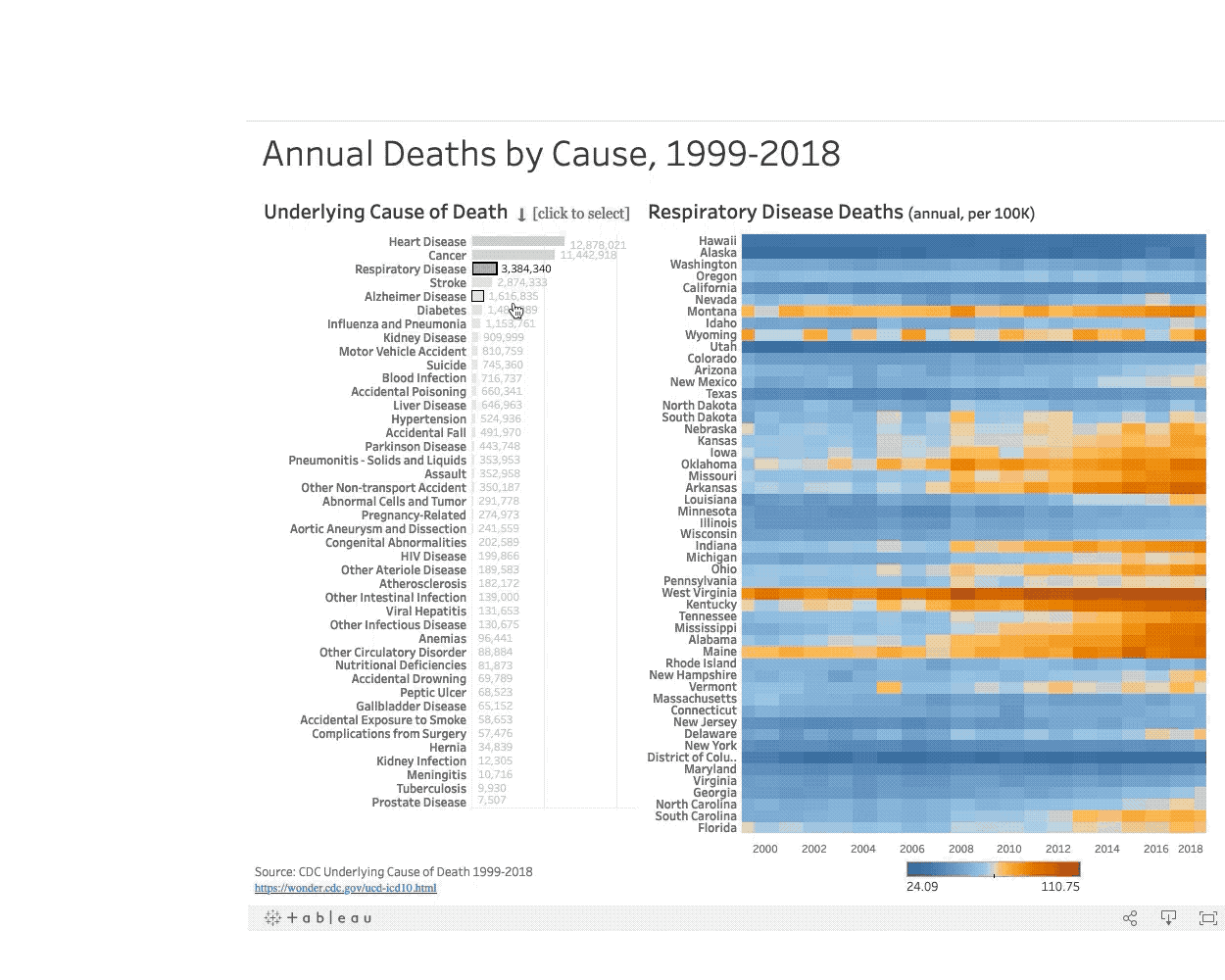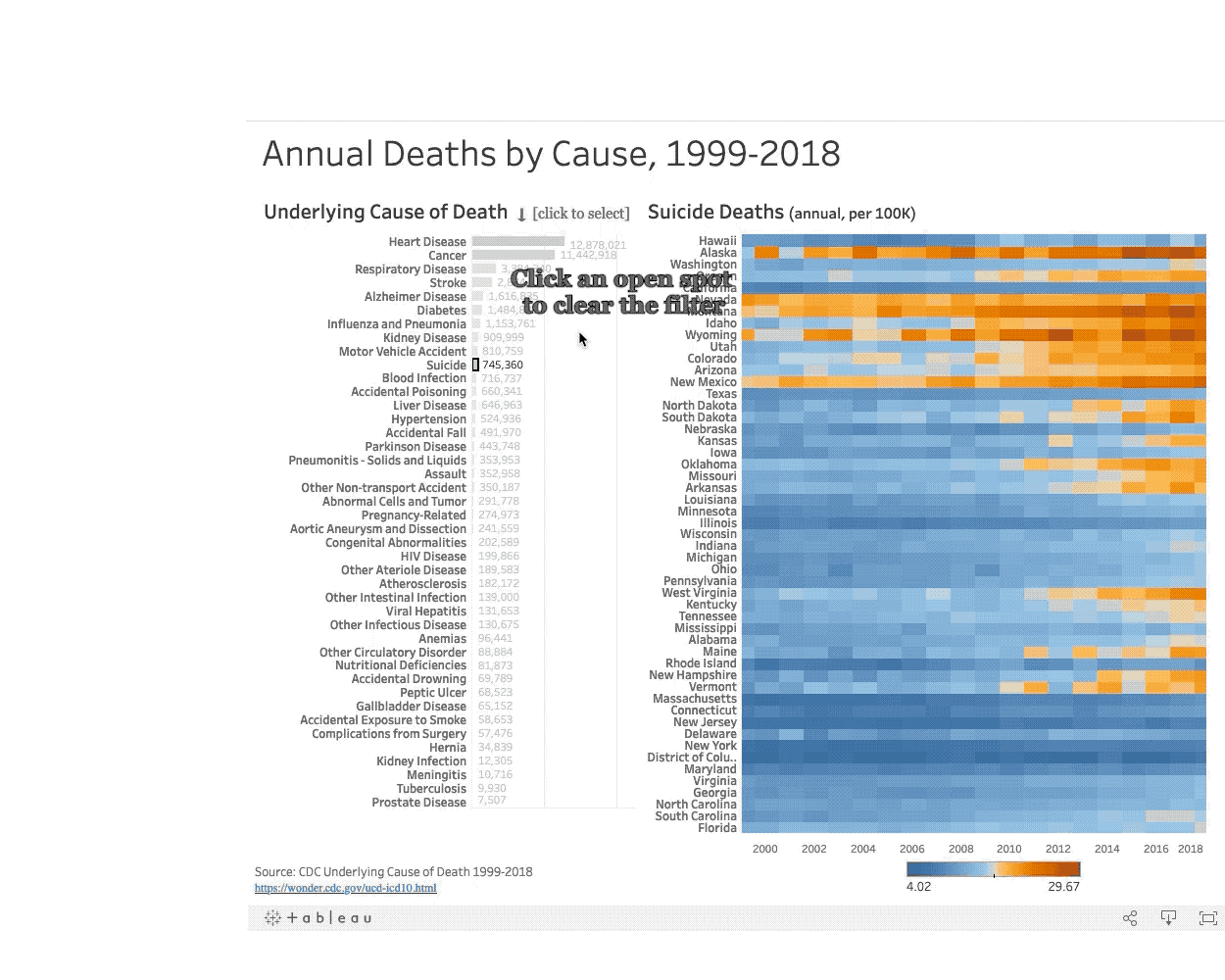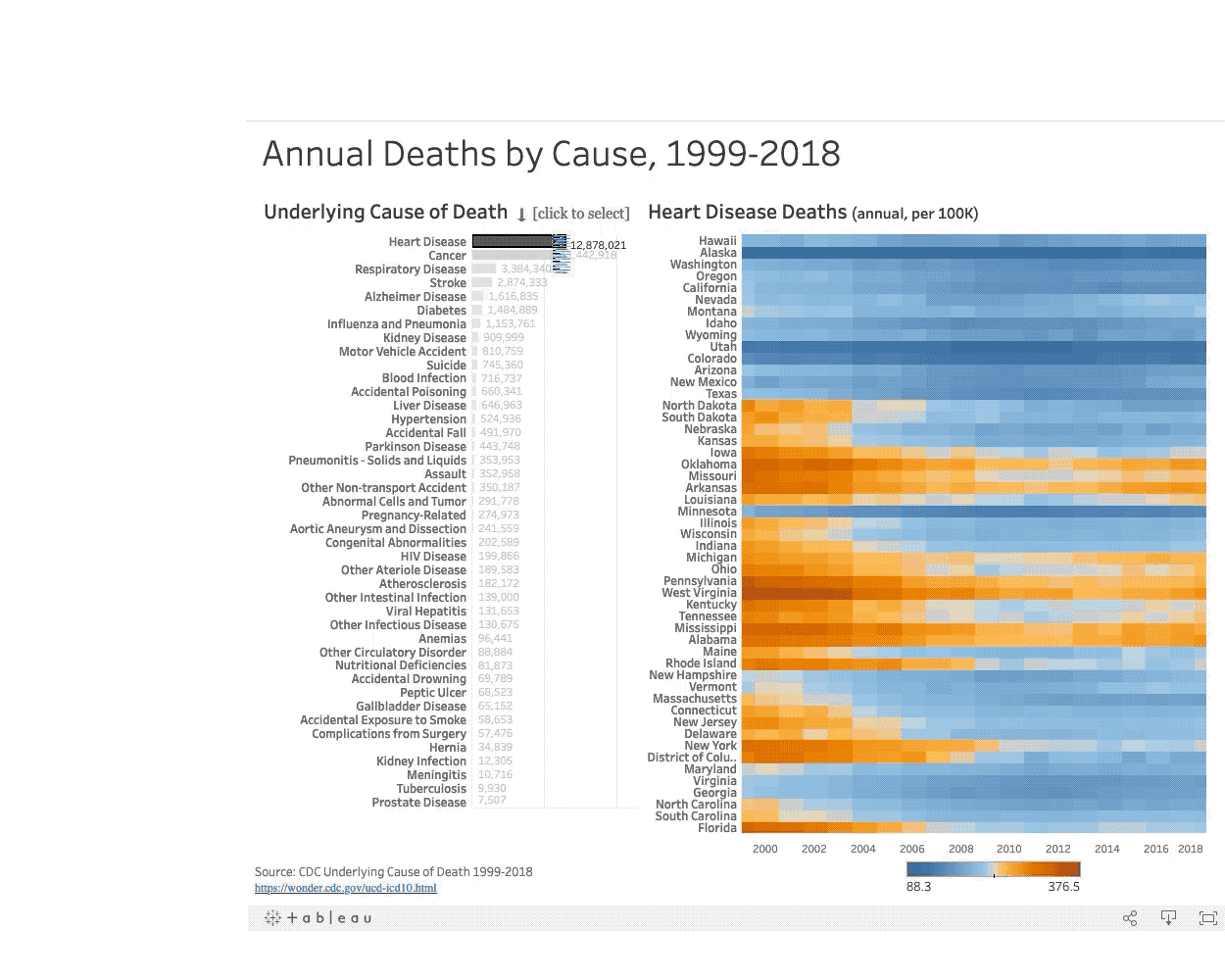
In the United States 50 million people died between 1999-2018. What did they die from? Read more
In this interactive visualization the viewer is encouraged to explore leading causes of death in the United States and compare death rates along geographic regions to learn more about where they happen, and when, to inform public policy.
The exploration yields key insights that show a geographic and seasonal correlation to the prevelance of certain types of disease. For example, by exploring the geographic heatmap the viewer can see clusters of states that have lower economic activity also show a higher incidence of deaths caused by diabetes.
 Tableau
Tableau
 Tableau Desktop
Tableau Desktop
 Tableau Prep
Tableau Prep
 TabPy
TabPy
 JavaScript
Python
JavaScript
Python
 Data Vis Analysis Framework
Data Vis Analysis Framework
 National Center for Health
Statistics
National Center for Health
Statistics
Data Visualization | D3.js
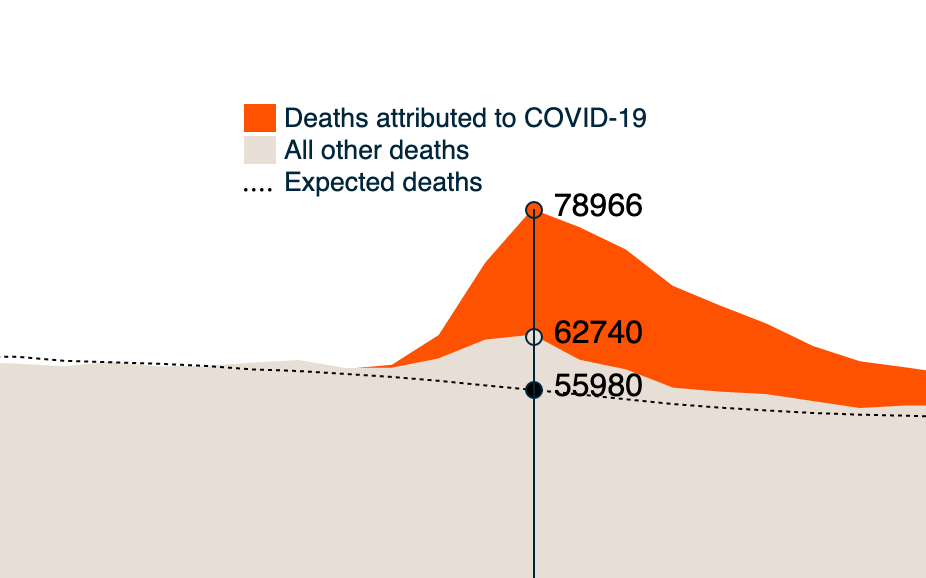
Are deaths from COVID-19 being undercounted or overcounted? One way to understand the accuracy in classification is by taking a view of excess deaths. Read more
Excess deaths are defined as the difference between observed deaths and expected deaths based on historic norms. Because cause of death can often include co-morbidities, a view of all causes can provide insights about the proportion of deaths that may be misclassified as they pertain to COVID-19.
In this interactive data visualization viewers gain insights into excess deaths as reported by all 50 states over time; moreover, the visualization allows the viewer to see that excess deaths can reasonably be attributed to COVID-19.
D3.js
Flask
JavaScript
Python
Data Vis Analysis Framework
 Centers for Disease Control
Centers for Disease Control
Applied Machine Learning

The malware industry continues to be a well-organized, well-funded market dedicated to evading traditional security measures. Once a computer is infected by malware, criminals can hurt consumers and enterprises in many ways. Read more
Microsoft takes this problem very seriously. As one part of their overall strategy for security, Microsoft challenged the data science community on Kaggle to develop techniques to predict if a machine will soon be hit with malware.
Over the course of three weeks, my team created two submission entries for Kaggle from our best performing models. We obtained results that surpassed our goal: 61.6% from the Light GBM method and 60.4% from our PyTorch Neural Net.
PyTorch
 LightGBM
LightGBM
 Jupyter
Python
Jupyter
Python
Data Engineering | Pipelines | Containers
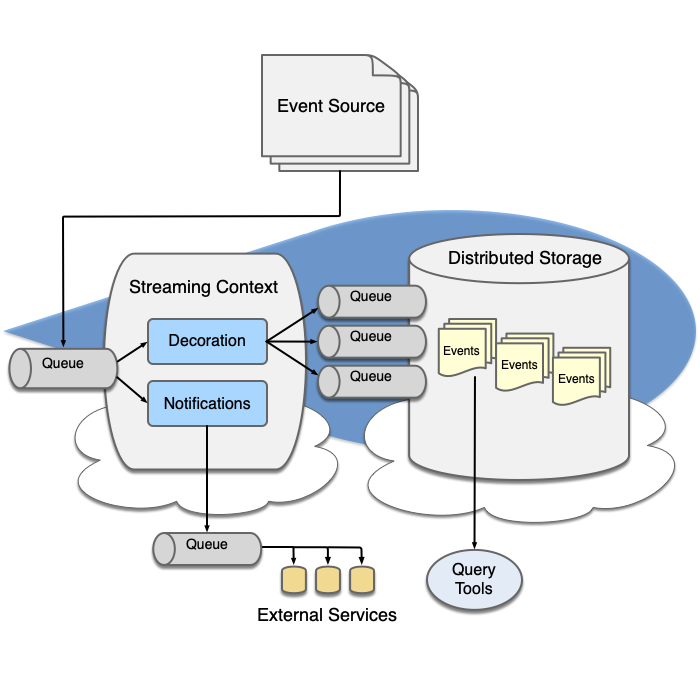
Roughly 80% of data science projects never make it into production. This is because the foundational underpinnings for storing, managing, and processing large datasets, and ensuring quality, security and availability lack a reliable and resilient infrastructure. Read more
Data engineering is the act of designing and building those reliable and resilient processes that transform and transport data along a series of "pipes" before arriving in a final state useful to data scientists.
Pipelines begin by ingesting data from many disparate sources where it is collected in raw form as a single source of truth. Then, as data is transported through the pipeline various data engineering tools and platforms are used to assemble, transform, connect and deliver data to the underlying storage and processing architectures needed by analytics and data science applications.
Below are some examples of constructing and consuming from a data pipeline.
 Google Cloud Platform
Google Cloud Platform
 Google BigQuery
Google BigQuery
 Docker Containers
Apache Spark
Docker Containers
Apache Spark
 Apache Kafka
Flask
Jupyter
Python
Data Pipelines
Apache Kafka
Flask
Jupyter
Python
Data Pipelines
Data Science Community

Data Science is a constantly evolving discipline. Practitioners need to participate in an active community to hone their craft. Berkeley Data is a hub for sharing knowledge, tools and resources within the Data Science community. Read more
Actively maintained on GitHub, Berkeley Data is an evolving body of work curated by current and former students of the Master's of Information and Data Science (MIDS) program at UC Berkeley. The repositories contain guidelines, procedures, and code that enable support of a data science practice.
Experiments & Causal Inference

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur in iaculis ex. Etiam volutpat laoreet urna. Morbi ut tortor nec nulla commodo malesuada sit amet vel lacus. Fusce eget efficitur libero. Morbi dapibus porta quam laoreet placerat.
Descriptive Statistics | R | LaTeX
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur in iaculis ex. Etiam volutpat laoreet urna. Morbi ut tortor nec nulla commodo malesuada sit amet vel lacus. Fusce eget efficitur libero. Morbi dapibus porta quam laoreet placerat.
Research Design | Bias | Ethics

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur in iaculis ex. Etiam volutpat laoreet urna. Morbi ut tortor nec nulla commodo malesuada sit amet vel lacus. Fusce eget efficitur libero. Morbi dapibus porta quam laoreet placerat.

Designed and built several revenue-enhancement and reporting systems for clients in the hospitality industry. Systems include Data Warehouses and custom applications providing forecasting, yield-management and revenue tracking for hotel managers and corporate revenue-management personnel.
Designed and built several system applications for an insurance industry client. Systems include a Data Warehouse for Investment Fund Performance Review and a variety of payroll, benefit and compensation applications for HR.
Delivered client projects for a software development consultancy startup, including work in insurance, banking, financial, reality, automotive, and records-retention fields.
Developed software modules for a railroad inspection and track-management system in C and RBASE.

Dean's List
Our partnership with Kevin has been
game-changing.
When Kevin first approached me with his
capstone project I knew we had to take
him up on his offer. In a matter of
weeks he helped us build something
massive that no one else has done.
Every
aspect of the project we worked on
together was more effective because of
the rigorous data science that Kevin
brought to the partnership. He has the
skills that could be used for most
anything. And he is a delight to work
with!
From Joyce's feedback on
Data Science Capstone:
I want to acknowledge how thorough this
plan is. It is well researched,
detailed, and well written. You have set
the bar for future students.
I met Kevin in the UC Berkeley Data
Science program where he took Deep
Learning for NLP. This is one of the
most advanced courses in the curriculum
and Kevin excelled.
As a
major component of this class students
submit a Deep Learning research project
to demonstrate their ability to
contribute to the field. Kevin’s team
produced a sophisticated adversarial
training framework, FireBERT, for
hardening BERT based algorithms against
adversarial attacks. Kevin was
responsible for the co-tuning strategy
of this project. His contributions stood
out not just for engaging in advanced DL
techniques, but also for the level of
engineering capabilities he
demonstrated.
He created a
repeatable process to set up and execute
the adversarial TextFooler algorithm for
the team. He was able to refactor the
original code to use PyTorch Lightning
to create consistently their classifier
models and train in different gpu
deployment environments. He also made
contributions to their SWITCH logic
utilizing base and abstract classes in
Python and implementing a random Search
routine for hyper-parameter
optimization.
The work Kevin
did in class showcases the sort of
skills I often seek when hiring industry
professionals, and I recommend him to
hiring managers looking for ML
engineers.
Kevin was a student in the Applied
Machine Learning class I was teaching as
part of Berkeley’s Masters in
Information and Data Science program.
From the start, it was clear that Kevin
was a highly capable student, achieving
top grades consistently. He was also
passionate about the topic, increasing
the quality of discussions in class with
thoughtful questions that provoke me and
his classmates to think about problems
in a different way.
After graduating from the program, Kevin
continued to pursue his passion in data
science and machine learning, embarking
on projects in data visualization,
research on adversarial ML, (even
publishing this work in a peer reviewed
journal!) and applying what he learned
in class to real world applications. He
is clearly in the top 1% of all students
that I’ve had the pleasure of
teaching.
Kevin’s aptitude in data science and
hustle in delivering on projects makes
him an invaluable asset.
Kevin is a brilliant technologist and
an exceptional leader, coach and
mentor.
He consistently
demonstrated a solid work ethic at
Redpoint plus a dedication to success.
Kevin is self-motivated,
methodical and very capable. It was a
pleasure to have Kevin on my team and I
would welcome the opportunity to work
with him again.
I had the pleasure of working with
Kevin during several discovery workshop
sessions.
Kevin expertly
worked with our clients to identify
requirements and was flexible during the
sessions to ensure the most relevant
topics were discussed.
Thanks to Kevin's leadership
during these sessions, the projects that
followed were able to get off to a great
start with clearly-defined requirements.
Kevin has strong technical skills and
informed business acumen.
He is incredibly talented and
persistent.
He's pleasant to work with and will be a
strong addition to any team.
I had the pleasure of meeting Kevin
when he was a student in my Machine
Learning course at Berkeley in the
Summer of 2020.
He not only
excelled in the course, he continued to
show his dedication to the work even
after the course was finished,
organizing a program wide course project
review encouraging others to learn from
each other's challenges and
experiences.
A true team
player!
Kevin was one of those students that
you dream to have in your classes.
His
thirst for knowledge and willingness to
invest the time and hard work needed to
master the most complicated concepts of
my classes made him stand out clearly.
He was a great driving force for the
group, always eager to ask more
questions, and share the answers he had
worked on.
From his work in
my class, it was evident that he is a
very insight driven individual, which
will define clear objectives in his work
and will lead the group through the
process of achieving them.
I taught Kevin Statistics for Data
Science for the UC Berkeley Masters in
Data Science program.
Even as
a student I easily saw how professional
and capable Kevin is. His is a very good
R coder, he can think critically and
break down mathematical concepts, and he
is enthusiastic about collaborative
work.
He works with a good
measure of both ability and humility.
This makes him effective as an analyst
and data scientist. Kevin will be an
asset to any team.
Kevin was a student at the University
of California, Berkeley in the master's
of data science program.
More
specifically he was a student in my data
engineering course, which included
numerous skills, such as analysis,
cloud-based computing, virtual machines,
Docker containers, Linux, Python
object-oriented programming, source code
control, big data architecture (lambda),
and massively parallel processing using
Spark.
Kevin excelled in the
course, going above and beyond the
required elements.
I highly
recommend, without reservation, Kevin
Hartman.
Kevin is a consumate professional.
He
is warm, and kind and exceptionally
smart. His ability to listen,
collaborate and seek solutions is not
found often and his lifelong pursuit of
learning (evidenced by his recent
pursuit and accomplishments in Data
Science) make him an incredible asset to
any organization.
I'm proud
to have worked with him and even more to
call him a friend.
On our travels we inevitibly run into a complex problem. What problem did you see and how will you solve it?
If you have more than a few travel stories to exchange here are some times you can reach me.
Schedule a Meeting












{kind=link}